External databases in which we have collaborated
PTMcode v2: a resource for functional associations of post-translational modifications within and between proteins.
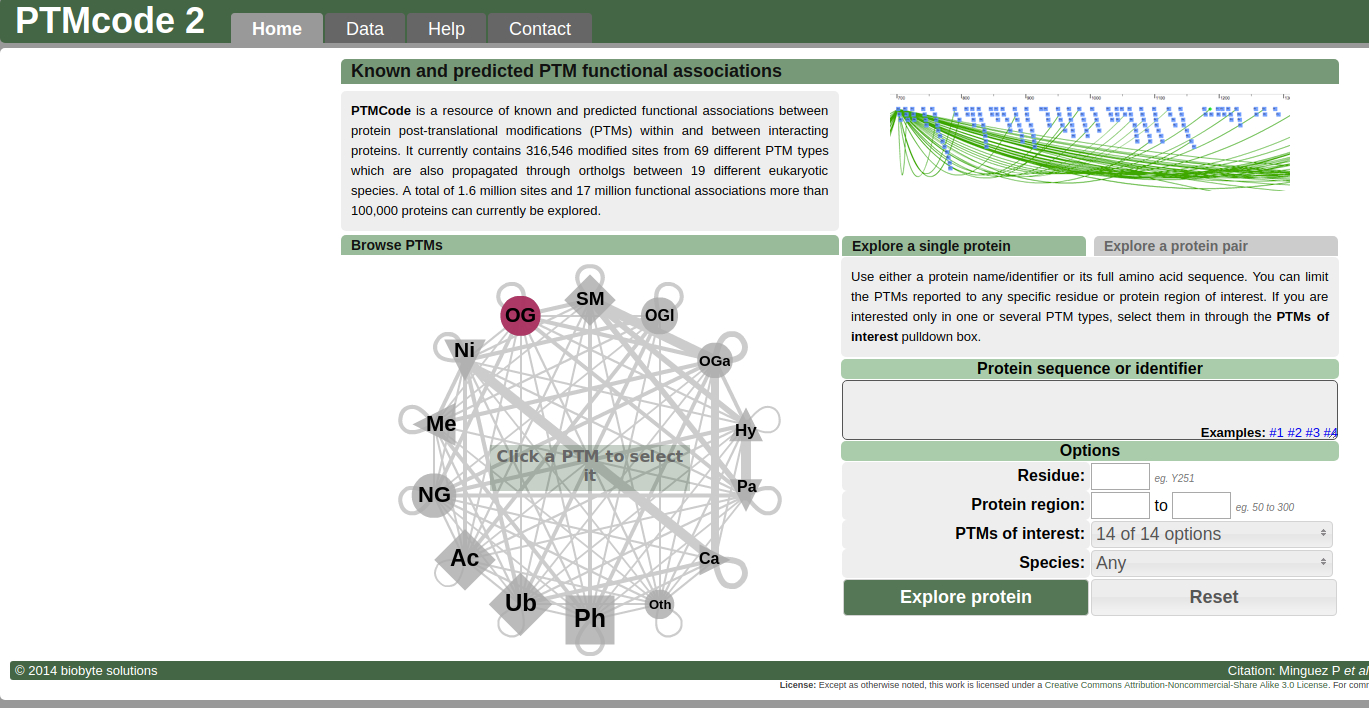
The post-translational regulation of proteins is mainly driven by two molecular events, their modification by several types of moieties and their interaction with other proteins. These two processes are interdependent and together are responsible for the function of the protein in a particular cell state. Several databases focus on the prediction and compilation of protein-protein interactions (PPIs) and no less on the collection and analysis of protein post-translational modifications (PTMs), however, there are no resources that concentrate on describing the regulatory role of PTMs in PPIs. We developed several methods based on residue co-evolution and proximity to predict the functional associations of pairs of PTMs that we apply to modifications in the same protein and between two interacting proteins. In order to make data available for understudied organisms, PTMcode v2 (http://ptmcode.embl.de) includes a new strategy to propagate PTMs from validated modified sites through orthologous proteins. The second release of PTMcode covers 19 eukaryotic species from which we collected more than 300 000 experimentally verified PTMs (>1 300 000 propagated) of 69 types extracting the post-translational regulation of >100 000 proteins and >100 000 interactions. In total, we report 8 million associations of PTMs regulating single proteins and over 9.4 million interplays tuning PPIs.
Implementation
PTMCode 2 is available at: http://ptmcode.embl.de/
Publication
Minguez P, Letunic I, Parca L, Garcia-Alonso L, Dopazo J, Huerta-Cepas J, Bork P. 2014. PTMcode v2: a resource for functional associations of post-translational modifications within and between proteins. 43:D494-D502
SNPeffect: on-line prediction of molecular and structural effects of protein-coding variants
Single nucleotide variants (SNVs) are, together with copy number variation, the primary source of variation in the human genome and are associated with phenotypic variation such as altered response to drug treatment and susceptibility to disease. Linking structural effects of non-synonymous SNVs to functional outcomes is a major issue in structural bioinformatics. The SNPeffect database uses sequence- and structure-based bioinformatics tools to predict the effect of protein-coding SNVs on the structural phenotype of proteins. It integrates aggregation prediction (TANGO), amyloid prediction (WALTZ), chaperone-binding prediction (LIMBO) and protein stability analysis (FoldX) for structural phenotyping. Additionally, SNPeffect holds information on affected catalytic sites and a number of post-translational modifications. The database contains all known human protein variants from UniProt, but users can now also submit custom protein variants for a SNPeffect analysis, including automated structure modeling. The new meta-analysis application allows plotting correlations between phenotypic features for a user-selected set of variants.
Implementation
SNPeffect is available at: http://snpeffect.switchlab.org
Papers available at: DeBaets et al., NAR 2012 and Reumers et al., 2008 NAR
DBAli: a database of pairwise and multiple protein structure alignments
Advances in structural biology have resulted in a rapid increase in the number of experimentally determined protein structures. There is a need for an up-to-date comprehensive database of pairwise and multiple structure-based alignments for families of related proteins as well as tools to automatically and comprehensively generate, store, and analyze these alignments. We aim to provide some of this functionality to the biological community.
DBAli stores pairwise comparisons of all structures in the Protein Data Bank calculated using the program MAMMOTH. It also contains multiple structure alignments generated by the SALIGN command of MODELLER. DBAli is updated weekly. As of August 2007, DBAli contains ~1.7 billion pairwise comparisons and over 12,500 family-based multiple structure alignments for ~35,000 non-redundant protein chains in the PDB.
DBAli, a database of pairwise and multiple structure alignments, also integrates tools for dynamically establishing relationships between protein structures and their fragments. The utility of the database is illustrated by outlining several of its current applications. The DBAli database is accessible via the World Wide Web at http://www.dbali.org

SARA: a server for function annotation of RNA structures
Recent interest in non-coding RNA transcripts has resulted in a rapid increase of deposited RNA structures in the Protein Data Bank. However, a characterization and functional classification of the RNA structure and function space have only been partially addressed. Here, we introduce the SARA program for pairwise alignment of RNA structures as a web server for structure-based RNA function assignment.
The SARA server relies on the SARA program, which aligns two RNA structures based on a unit-vector root mean square approach. The likely accuracy of the SARA alignments is assessed by three different p-values estimating the statistical significance of the sequence, secondary structure and tertiary structure identity scores, respectively. Our benchmarks, which relied on a set of 419 RNA structures with known SCOR structural class, indicate that at a negative logarithm of mean p-value of 2.5 or higher, SARA can assign the correct or a similar SCOR class to 81.4% and 95.3% of the benchmark set, respectively.

Implementation
more info at: SARA server